广泛收集国内外的混凝土构件试验数据,采用机器学习方法,建立混凝土构件纵筋及箍筋的预测模型,实现混凝土框架柱和剪力墙边缘构件智能设计。
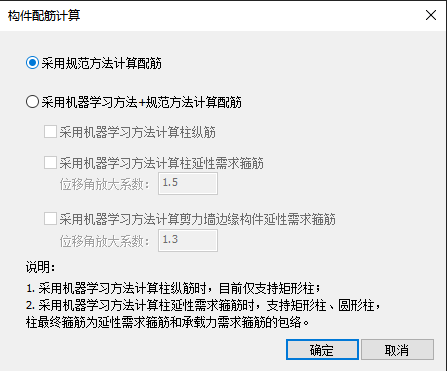
图106 构件配筋计算
菜单:【设计报告】→【设计】→【配筋计算】
构件默认配筋方法为规范方法。
目前机器学习方法仅支持计算混凝土柱纵筋、箍筋以及剪力墙边缘构件箍筋,用户只需勾选相应的选项即可。对于未列出及未勾选项的构件,程序仍采用规范方法进行配筋。
勾选“采用机器学习方法计算柱纵筋”或“采用机器学习方法计算柱延性需求箍筋”时,计算结果可以在配筋结果及数据文件中进行查看。勾选“采用机器学习方法计算剪力墙边缘构件延性需求箍筋”时,计算结果保存在工程目录下“工况名称_AsvWall.csv”文件中。
位移角放大系数:用户可以输入位移角放大系数,对程序根据时程分析得到的构件位移角进行放大,程序会根据放大以后的位移角计算配筋。
构件极限位移角对应构件比较严重损坏和严重损坏的界线值,可根据构件性能目标对构件位移角需求进行放大。为使竖向承重的关键构件框架柱损坏程度控制在中度损坏及以下,将框架柱极限位移角需求近似放大1.5倍[10],将剪力墙极限位移角需求近似放大1.3倍[11]。
由于构件延性变形能力受轴压比、箍筋用量、箍筋分布和间距、箍筋强度、混凝土强度、剪跨比、纵筋配筋率、截面形状等众多因素影响,且各影响因素相互关联,导致箍筋设计难有准确的计算方法,经验公式结果离散性很大。近年来,随着计算机计算能力的大幅提升和人工智能技术的快速发展,基于机器学习的非参数模型在试验数据充分、机理复杂的领域得到了广泛的应用,取得了丰硕的成果。相比于经验模型,机器学习具有以下优点:(1)具有强大的捕捉输入和输出变量之间复杂非线性关系的能力;(2)可以处理大量输入变量,避免忽略潜在的重要变量;(3)可以考虑试验样本的多样性,从海量数据中深入挖掘信息。因此,有必要尝试采用机器学习方法来预测钢筋混凝土构件所需的箍筋用量。
文献[12]基于326个矩形柱和172个圆形柱组成的试验数据库(共498个样本),系统地进行了特征工程,包括数据转换、特征提取、特征选择和特征迭代,训练了包括普通最小二乘法、Lasso回归、岭回归、K-最近邻、支持向量回归、多层感知器、决策树、随机森林、AdaBoost、XGBoost、LightGBM和CatBoost在内的12个机器学习模型。采用网格搜索和十折交叉验证方法进行机器学习模型超参数调优。通过在测试集上的综合性能评价,选择XGBoost模型作为最终的推荐模型,并采用SHAP方法和部分依赖图(PDP)验证了机器学习模型的可靠性。
文献[13]基于501个剪力墙试件,通过特征升维得到52个输入参数,经过特征降维得到六个特征组成的最简特征子集。采用网格搜索和十折交叉验证方法进行超参数调优,通过在测试集上的综合性能评价,从十一种模型中选出选择XGBoost模型作为最终的推荐模型。与经验模型相比,该模型具有更高的精度和更低的离散性。同时,该模型能够捕捉影响因素与配箍之间的非线性关联,充分考虑了各影响因素对剪力墙边缘构件配箍的影响。
框架梁配箍率预测模型尚在研发中,目前采用钱稼茹等[14]基于大量试验研究数据采用统计回归方法获得的钢筋混凝土框架梁配箍特征值计算公式:
式中:为框架梁配箍特征值;为位移角需求;为相对受压区高度;为剪跨;为截面有效高度;、分别为受拉钢筋和受压钢筋配筋率;为纵筋屈服强度;为混凝土受压强度;为系数,对强度等级不超过C50的混凝土,可取0.797。
展开
- SAUSAGE 2025
- 第1章 前 言
- 第2章 目 录
- 第3章 基本约定与应用范围
- 第4章 软件运行环境
- 第5章 操作界面
- 5.0.1 构件属性
- 5.0.2 单元属性
- 5.0.3 模型图形
- 5.0.4 后处理云图
- 5.0.5 解锁模型
- 5.0.6 图元捕捉功能
- 5.0.7 图元显示功能
- 5.0.8 楼层显示
- 5.0.9 显示设置
- 5.0.10 图形标注功能
- 5.0.11 视图设置
- 5.0.12 后处理设置
- 5.0.13 图例设置
- 第6章 建立模型
- 6.0.14 导入SATWE
- 6.0.15 导入PMSAP
- 6.0.16 导入MIDAS
- 6.0.17 导入ETABS
- 6.0.18 导入SAP2000
- 6.0.19 导入YJK
- 6.0.20 模型组装
- 6.0.21 导出ABAQUS
- 6.0.22 全楼参数
- 6.0.23 轴网
- 6.0.24 编辑
- 6.0.25 基本
- 6.0.26 材料
- 6.0.27 构件
- 6.0.28 模型优化
- 6.0.29 隔墙
- 6.0.30 组件
- 6.0.31 选取
- 6.0.32 搜索
- 6.0.33 构件属性修改
- 6.0.34 其它属性修改
- 6.0.35 初始缺陷
- 6.0.36 边界条件
- 6.0.37 刚度系数
- 6.0.38 点
- 6.0.39 梁、柱、斜撑
- 6.0.40 板
- 6.0.41 墙
- 6.0.42 边缘构件
- 6.0.43 虚梁、连梁纵筋
- 6.0.44 减隔震构件
- 第7章 荷载
- 7.0.45 点荷载
- 7.0.46 梁荷载
- 7.0.47 柱荷载
- 7.0.48 斜撑荷载
- 7.0.49 板荷载
- 7.0.50 墙荷载
- 7.0.51 导荷方式
- 7.0.52 线
- 7.0.53 面
- 第8章 分析
- 8.0.54 求解设备
- 8.0.55 构件组
- 8.0.56 施工阶段
- 8.0.57 输出设置
- 8.0.58 阻尼位置
- 8.0.59 性能评价
- 8.0.60 分析参数
- 8.0.61 检查模型
- 8.0.62 生成网格
- 8.0.63 修改网格
- 8.0.64 网格质量
- 8.0.65 步长优化
- 8.0.66 一键初始分析
- 8.0.67 线性屈曲
- 8.0.68 选择地震动
- 8.0.69 地震波分析工具
- 8.0.70 动力非线性分析
- 8.0.71 一致激励分析
- 8.0.72 多点激励分析
- 8.0.73 实时模态分析
- 8.0.74 静力推覆分析
- 第9章 初始结果
- 9.0.75 重力变形
- 9.0.76 支座反力
- 9.0.77 构件内力
- 9.0.78 初始模态
- 9.0.79 初始周期
- 9.0.80 最大频率模态
- 9.0.81 最大频率
- 9.0.82 屈曲模态
- 9.0.83 屈曲特征值
- 9.0.84 缺陷显示
- 9.0.85 缺陷编辑
- 第10章 动力结果
- 10.0.86 重新统计
- 10.0.87 工况包络
- 10.0.88 层间位移
- 10.0.89 自定义层间位移
- 10.0.90 楼层加速度
- 10.0.91 层间剪力
- 10.0.92 倾覆力矩
- 10.0.93 自定义层间剪力
- 10.0.94 基底剪力
- 10.0.95 位移时程
- 10.0.96 滞回曲线
- 10.0.97 能量图
- 10.0.98 截面切割
- 10.0.99 节点位移
- 10.0.100 分组结果
- 10.0.101 损伤
- 10.0.102 钢筋塑性应变
- 10.0.103 钢材塑性应变
- 10.0.104 单元性能
- 10.0.105 构件性能
- 10.0.106 实时模态
- 10.0.107 减隔震装置
- 10.0.108 PMM曲线
- 10.0.109 构件内力
- 10.0.110 构件组内力
- 第11章 静力结果
- 11.0.111 重新统计
- 11.0.112 工况包络
- 11.0.113 加载曲线
- 11.0.114 静力推覆曲线
- 11.0.115 节点位移
- 11.0.116 钢材应力应变
- 11.0.117 钢筋塑性应变
- 11.0.118 损伤
- 11.0.119 分组结果
- 11.0.120 单元性能
- 11.0.121 构件性能
- 11.0.122 构件内力
- 11.0.123 构件组内力
- 第12章 设计报告
- 12.0.124 数据文件
- 12.0.125 综合报告
- 12.0.126 配筋计算
- 12.0.127 配筋显示
- 12.0.128 性能验算
- 12.0.129 正截面验算
- 12.0.130 抗剪承载力验算
- 12.0.131 抗剪截面验算
- 12.0.132 偏拉验算
- 12.0.133 轴压验算
- 12.0.134 构件位移角
- 12.0.135 其他指标
- 第13章 选项
- 13.0.136 构件模式
- 13.0.137 显示/隐藏
- 13.0.138 楼层显示
- 13.0.139 系统参数
- 13.0.140 清除标注
- 13.0.141 字体缩放
- 13.0.142 平面文字
- 13.0.143 属性
- 13.0.144 编号
- 13.0.145 三维视图
- 13.0.146 断面图
- 13.0.147 视图变换
- 13.0.148 图形旋转
- 13.0.149 图形移动
- 第14章 培训教程
- 14.0.150 修改几何结构
- 14.0.151 统一设置模型参数
- 14.0.152 生成剪力墙边缘构件
- 14.0.153 设置施工模拟加载
- 14.0.154 划分有限元网格
- 14.0.155 初始模态分析
- 14.0.156 最大频率分析
- 14.0.157 竖向加载分析
- 14.0.158 选择地震动
- 14.0.159 动力时程分析
- 14.0.160 层间位移角
- 14.0.161 层间剪力
- 14.0.162 倾覆力矩
- 14.0.163 基底剪力
- 14.0.164 节点位移
- 14.0.165 数据文件
- 14.0.166 图形结果
- 14.0.167 模型整体特征对比
- 14.0.168 楼层反应对比
- 14.0.169 损伤反应对比
- 第15章 软件分析技术条件
- 15.0.170 项目定义
- 15.0.171 截面定义
- 15.0.172 配筋
- 15.0.173 剖分纤维
- 15.0.174 几何构造关系
- 15.0.175 自动生成边缘构件
- 15.0.176 跨层竖向构件连接算法
- 15.0.177 层内组合墙连接算法
- 15.0.178 Delauney三角形网格自动剖分
- 15.0.179 四边形和三角形网格自动剖分步骤
- 15.0.180 混凝土一维本构关系
- 15.0.181 钢筋一维本构关系
- 15.0.182 混凝土二维本构关系
- 15.0.183 钢材二维本构关系
- 15.0.184 约束混凝土本构模型
- 15.0.185 砌体材料
- 15.0.186 剪切非线性
- 15.0.187 梁单元
- 15.0.188 杆单元
- 15.0.189 壳单元
- 15.0.190 速度型阻尼器
- 15.0.191 位移型阻尼器
- 15.0.192 自定义阻尼器
- 15.0.193 隔震支座
- 15.0.194 三向耦合隔震支座
- 15.0.195 防屈曲支撑
- 15.0.196 Wen模型
- 15.0.197 线性弹簧
- 15.0.198 拉索
- 15.0.199 钩
- 15.0.200 间隙
- 15.0.201 摩擦摆支座
- 15.0.202 有限元单元类型设置
- 15.0.203 积分方案
- 15.0.204 分析基本假定
- 15.0.205 计算流程
- 15.0.206 模态分析
- 15.0.207 分施工阶段进行竖向荷载加载
- 15.0.208 竖向荷载的找平
- 15.0.209 显式时程分析
- 15.0.210 振型阻尼
- 15.0.211 简化振型阻尼
- 15.0.212 显式时程分析中的应变计算及大位移效应
- 15.0.213 隐式时程分析
- 15.0.214 能量
- 15.0.215 迭代求解器
- 15.0.216 传统的算法
- 15.0.217 改进后的竖向加载算法
- 15.0.218 直接求解器
- 15.0.219 初始缺陷
- 15.0.220 风荷载计算
- 15.0.221 减震结构附加阻尼比计算
- 15.0.222 构件内力和配筋
- 15.0.223 推覆分析性能点查找方法
- 15.0.224 PMM曲线计算
- 15.0.225 隔墙等效斜撑宽度计算方法
- 第16章 附录一 参数说明
- 第17章 附录二 工具栏功能说明
- 第18章 附录三 快捷键说明
- 第19章 结束语
暂无相关搜索结果!
